【5.4.2.4】Codon optimization(19年基于二级结构优化密码子的开源工具)
Codon optimization based on the mRNA folding energy and the codon frequency
一、安装
开源的工具:
https://github.com/yutaka-saito/codon_optimization
--cai_thsh
Threshold of CAI
default: 0.75
--rcc_thsh
Threshold of the rare codon count
default: 0
--adptw_thsh
Threshold of the normalized codon frequency for defining rare codons
二、算法介绍
通过同义词替换(synonymous substitution )进行的密码子优化已广泛用于重组蛋白表达。最近的研究已经研究了基于大规模表达分析的密码子优化的序列特征。但是,这些研究仅限于常见的宿主生物,例如大肠杆菌。在这里,我们为红球红球菌(一种革兰氏阳性富含GC的放线菌)作为替代宿主生物引起了人们的关注,开发了一种密码子优化方法。我们用相同的质粒载体评估了R. erythropolis中204基因的重组蛋白表达。这些表达数据的统计分析表明,在5’区域的mRNA折叠能以及密码子频率是密码子优化的重要序列特征。有趣的是,其他序列特征(例如密码子重复率)显示出与先前对大肠杆菌的研究不同的趋势。我们针对这些序列特征优化了12个基因的编码序列,并确认其中9个(75%)与野生型序列相比可提高表达水平。尤其是,对于野生型序列的表达水平很小或无法检测的5个基因,所有这些都可以通过优化序列来改善。这些结果证明了我们的密码子优化方法在R. erythropolis和其他放线菌中的有效性。
2.1 前言
利用细菌和其他宿主生物进行重组蛋白表达是生产蛋白的一项基本技术。重组蛋白表达的关键步骤是密码子优化,其中目的蛋白的编码序列通过同义词替换设计,旨在提高其表达水平2。
当前的密码子优化方法基于影响蛋白质表达水平的序列特征:
- 常规方法是根据宿主生物中的基因组密码子用法,用频繁的密码子代替稀有密码子。该方法的基础是其编码序列由频繁的密码子组成的内源基因具有较高的蛋白质表达水平,因此重组蛋白质的表达也被认为可以通过增加密码子频率来改善。
- 另一种方法是引入在计算上可预测的破坏mRNA二级结构的同义词。由于稳定的mRNA二级结构可能抑制翻译,因此该方法被认为可以通过提高翻译效率来改善重组蛋白的表达。
这些序列特征和蛋白质表达水平之间的关联已通过内源(endogenous)基因的组学分析表明。另一方面,使用相对少量的基因已显示出它们对重组蛋白表达有影响的直接证据。
最近,重组蛋白表达的大规模分析揭示了密码子优化的序列特征,史无前例的细节[9,10]。在这些研究中,使用相同的宿主生物和相同的质粒载体,系统地评估了数千个基因的重组蛋白表达。然后,通过统计分析研究了各种序列特征对蛋白质表达水平的影响。该策略提供了对常规使用的序列特征的新见解,例如:
- 取决于序列位置(例如5’区域或其他)的密码子频率的影响。
- 另外,已经显示了多种新的序列特征是重要的,包括使用特定的双密码子和在相邻位置重复出现密码子。
然而,迄今为止,此类研究仅限于常见的宿主生物,例如大肠杆菌,这提出了一个问题,即这些序列特征是否也可用于研究较少的宿主生物中的密码子优化。
红球红球菌(Rhodococcus erythropolis)是一种富含革兰氏阳性且富含GC的放线菌,已被用作宿主生物进行重组蛋白表达和异源生产抗菌化合物。 R. erythropolis在4至35°C的较宽温度范围内生长并产生重组蛋白,与其他宿主生物(例如大肠杆菌(革兰氏阴性细菌),芽孢杆菌和乳球菌)相比,其胞内环境有所不同。具有中等GC含量的阳性细菌)。由于这些特征,红细菌可以产生难以在大肠杆菌中表达的重组蛋白。还已经证明,R。erythropolis可从结核分枝杆菌产生细菌脂糖蛋白,由于其翻译后修饰无法在大肠杆菌中表达[16]。基于这些性能,红细菌被认为是替代的下一代宿主微生物。
在这里,我们基于对R. erythropolis和同一质粒载体使用的204个基因的重组蛋白表达数据的统计分析,开发了一种密码子优化方法。统计分析表明,mRNA在5’区域的折叠能和密码子频率是密码子优化最重要的序列特征。有趣的是,其他序列特征(包括密码子重复率)显示出与大肠杆菌不同的趋势,表明它们对蛋白质表达水平的影响具有物种特异性。我们基于这些序列特征的优化设计了选定基因的编码序列,并证明了与野生型序列相比,它们大多数都表现出了更高的表达水平。
2.2 结果
红细菌中重组蛋白表达数据集
为了开发红细菌的密码子优化方法,我们试图研究影响蛋白质表达水平的序列特征。 为此,我们评估了R. erythropolis中204个基因的重组蛋白表达(补充数据S1)。 这些基因选自天蓝色链霉菌,并使用pTip质粒载体在异红球菌中异源表达。 该表达系统使我们能够评估在同一启动子转录下各种基因的重组蛋白表达,从而关注它们在翻译效率上的差异。 根据SDS-PAGE凝胶的目视检查(补充图S1),蛋白表达水平通过整数评分:1(低或未检测到),2(中)和3(高)进行评分。 注意,在以前的大肠杆菌研究中也采用了这种离散评分方案。
影响蛋白质表达水平的序列特征的统计分析
我们使用我们的数据来分析序列特征对蛋白质表达水平的影响。我们考虑了各种序列特征,包括:
- 密码子频率的度量,例如密码子适应指数(CAI)和tRNA适应指数(tAI),
- 以及密码子重复出现的度量,例如密码子重复率和氨基酸重复率。
- 此外,通过EnSembleEnergy程序在RNAStructure软件包中预测的折叠能(ΔGUH)测量了5’区mRNA二级结构的稳定性。为了计算ΔGUH,将5’区定义为pTip质粒载体中的5’非翻译区(UTR),加上编码序列开头的33个核苷酸。
计算的特征值汇总在补充数据S1中。对于每种类型的序列特征,在特征值和蛋白质表达水平之间评估了多序列相关系数20(图1a)。检测到CAI,tAI和ΔGUH的正相关系数,这与先前关于大肠杆菌的报道一致。有趣的是,密码子重复率和氨基酸重复率的结果显示出与大肠杆菌不同的趋势。虽然据报道这些序列特征与大肠杆菌中的蛋白质表达水平呈负相关,但我们在红球藻中的研究结果显示出正相关系数,暗示了这些序列特征的物种特异性影响。补充图S2总结了我们在红球藻中的研究结果与先前在大肠杆菌中的研究之间的比较。 CAI和ΔGUH不仅是红细菌中的重要因素,而且在大肠杆菌中也是重要的因素。另一方面,与R.erythropolis相比,大肠杆菌中密码子重复率和氨基酸重复率的贡献更大。
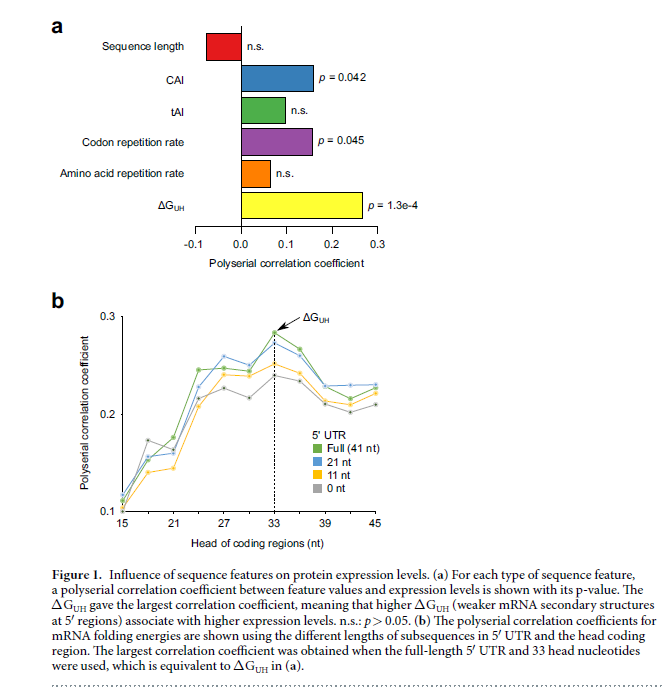
在所考虑的序列特征中,ΔGUH显示出最大的相关系数,表明在5’区域较高的mRNA折叠能(即较弱的mRNA二级结构)导致蛋白质表达水平提高。 通过改变5’区域的定义进一步研究了mRNA折叠能的影响(图1b)。 对于全长5’UTR加33个头部核苷酸的ΔGUH,相关系数最大,而使用延伸的或截短的5’区域则无法获得较大的相关系数。 这些结果促使我们开发基于ΔGUH的密码子优化方法。 除了ΔGUH,CAI还显示出第二大的相关系数,这表明频繁使用密码子(frequent codons)对增加蛋白质表达水平也有效。
H方法:基于mRNA折叠能的密码子优化
我们首先设计了一种仅基于ΔGUH的密码子优化方法,我们将其命名为“ H-method”。 对于给定的蛋白质,H-方法计算地产生关于33个头部核苷酸的所有可能的同义变体的编码序列。 然后,H方法为每个同义变体计算ΔGUH,并提出具有最高ΔGUH的编码序列。
我们注意到H方法仅将突变引入33个头部核苷酸(即11个密码子),而下游核苷酸未修饰。因此,所产生的同义变体的数目可以保持相对较小,这允许我们计算关于33个头部核苷酸的所有可能的同义变体的ΔGUH。当整个编码序列被突变时,这种详尽的计算是不可行的,因为可能的同义变体的数量随序列长度呈指数增加。关注头部核苷酸的优点不仅是计算成本,而且是实验成本。如果密码子优化修饰了整个编码序列,我们需要使用全长基因合成,这需要相对较高的实验成本。相反,可以通过基于引物的诱变来进行头部核苷酸的修饰,该引物比全长基因合成(方法)便宜得多。如稍后所示,这使我们能够使用大量序列来测试方法的有效性。如此低的实验成本对于促进密码子优化的广泛适用性很重要。
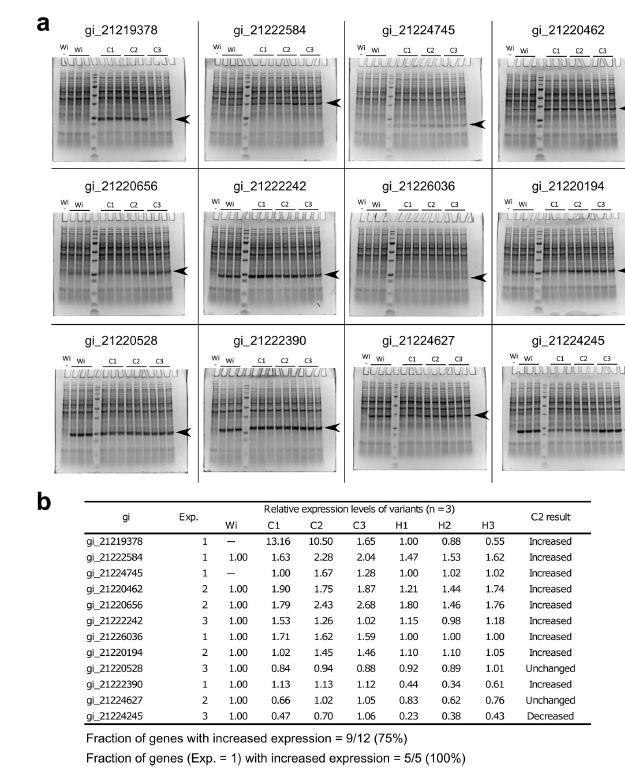
为了测试H方法的有效性,我们使用H方法设计基因的编码序列,并比较了优化序列和野生型序列之间的蛋白质表达水平。我们选择了12个基因,以便在密码子优化之前其蛋白质表达水平发生变化:5个得分为1(低或未检测到)的基因,4个得分为2(中)的基因和3个得分为3(高)的基因。 )。对于每个基因,我们使用H方法(H1-3)设计了3个序列,其ΔGUH位居第一至第三。为了进行比较,我们还设计了3个序列,其ΔGUH值从第一到第三低(即非优化序列; L1-3)。使用pTip质粒载体将这些序列转化为红球菌(R. erythropolis)(图2a),并使用三个生物学复制品测量蛋白质表达水平(图2b)。总之,与野生型序列相比,优化的序列在12个基因中有6个显示出增加的表达水平。但是,对于其余的6个基因,未观察到蛋白质表达的改善。这些结果证明了H方法的有效性,同时表明了它在成功率方面的局限性。 ΔGUH在密码子优化中的作用还受到反优化序列的支持,该序列的蛋白质表达水平相对于所有12个基因的野生型序列均显着降低。


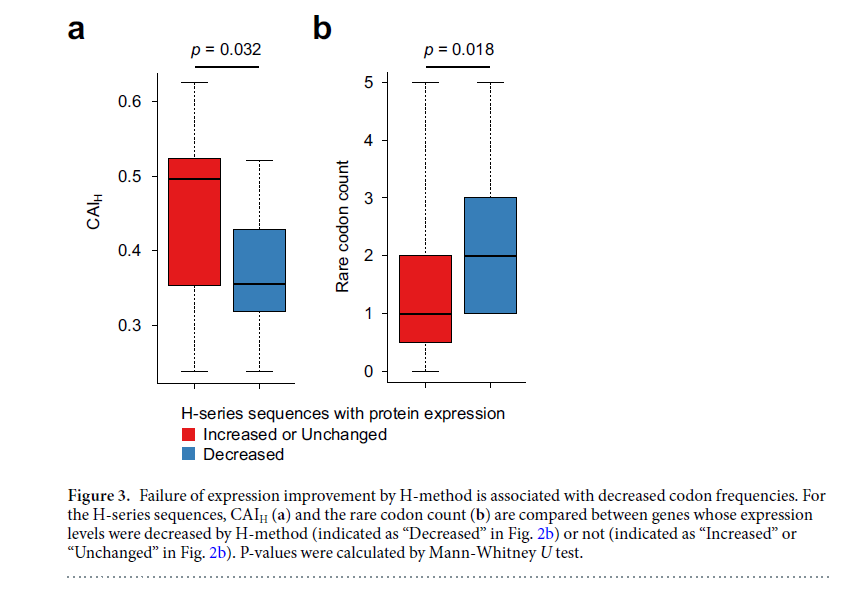
为了调查H方法不能改善蛋白质表达的原因,我们记得CAI在ΔGUH之后显示第二大相关系数(图1a)。因此,我们假设由H方法引入的突变可能会降低CAI,从而导致蛋白质表达水平降低。为了验证这一假设,我们计算了H-方法设计的编码序列的CAI(仅关注33个头部核苷酸(CAIH))。在蛋白质表达水平降低或未降低的两组基因之间比较了CAIH(图3a)。我们还测量了33个头部核苷酸中使用的稀有密码子的数量(图3b;补充数据S2),其中稀有密码子定义为TTA,ATA和AGA,其标准化密码子频率小于0.1(方法)。实际上,与其他基因相比,由H方法设计的编码序列显示出蛋白质表达水平降低的基因具有较小的CAIH和更多的稀有密码子。这些结果表明,通过组合ΔGUH和CAIH,可以开发出更强大的密码子优化方法。
C方法:结合mRNA折叠能和密码子频率的密码子优化
为了提高密码子优化方法的成功率,我们接下来设计了一种结合了ΔGUH和CAIH的方法,我们将其命名为“ C方法”。与H方法相似,C方法从同义变体中提出了关于33个头部核苷酸的ΔGUH最高的编码序列。但是,生成的同义变体受到限制,因此它们的CAIH大于用户指定的阈值,并且不包含稀有密码子。这种方法使我们能够在控制CAIH的同时设计具有高ΔGUH的编码序列(补充图S3)。
我们通过类似于H方法的实验测试了C方法的有效性(图4a)。对于每个基因,使用CAIH的不同阈值通过C方法设计3个序列:0.60(C1),0.75(C2)和0.90(C3)。 C方法比H方法取得了更好的成功率(图4b)。对于C2序列,蛋白质表达水平在12个基因中的9个中增加了(75%)。令人惊讶的是,当关注野生型序列蛋白表达水平低或无法检测的5个基因时,所有这些都通过优化序列得到了改善。对于C1和C3序列,在每种情况下12个基因中的8个都得到了改善,显示成功率略低于C2序列。但是,仍然观察到野生型表达水平较差的所有5个基因的改善。这些结果证明了C-方法对改善重组蛋白在红细菌中的表达的有效性。
由于C方法使用CAIH阈值作为参数,因此在将C方法应用于其他基因和/或宿主生物时,我们需要选择CAIH阈值的标准。为此,我们进行了以下分析。首先,我们在密码子优化之前将C1,C2和C3序列的CAIH与相应的野生型序列进行了比较(图5a)。我们发现,C2序列平均具有与野生型序列相似的CAIH水平,而C1和C3序列在野生型分布中分别处于低端和高端。该结果提示了可以根据野生型基因表达序列的CAIH确定适当的CAIH阈值的标准。其次,我们将红,红细菌中C1,C2和C3的CAIH阈值与所有内源基因进行了比较(图5b)。我们发现,C2从内源基因分布的中位数适度较高,而C1和C3分别比中位数低和高得多。该结果表明另一个标准,即CAIH阈值应高于内源基因分布的中位数,同时避免极高的值。综上所述,我们建议选择CAIH阈值,以使其在很大程度上不偏离野生型序列和内源基因。我们还注意到,尽管C2在我们的验证实验中表现最佳,但C1和C3的性能与C2相似(图4b)。他们的成功率相当:C2(12个基因中的9个)与C1和C3(12个基因中的8个)。另外,野生型表达水平较差的所有5个基因不仅通过C2得到改善,而且通过C1和C3得到改善。因此,只要大致满足上述条件,CAIH阈值的精确值就不会严重影响C方法的性能。

2.3 讨论区
我们开发了一种密码子优化方法,可用于R. erythropolis(一种用于重组蛋白表达的有吸引力的宿主生物)中。该方法是基于对我们来自204个基因的重组蛋白表达数据的统计分析而开发的。所得的称为C方法的方法用于优化所选基因的编码序列,从而与野生型序列相比提高了蛋白质表达水平。我们的方法将是一种有用的工具,用于改善重组蛋白在红细菌中的表达,并可能在其他放线菌中的表达。
在重组蛋白表达数据的统计分析中,我们在红斑红球菌上的研究结果与先前对大肠杆菌的研究部分一致(图1a;补充图S2)。另一方面,我们观察到了关于密码子重复率和氨基酸重复率的物种特异性影响。尽管对这种物种特异性的解释并不简单,但我们提供了潜在的分子机制。首先,一些研究报道了一种称为密码子顺序的效应,其中重复使用相同类型的密码子可提高翻译效率。这些研究提出了一个模型,即如果这些相邻密码子对应于相同类型的tRNA,核糖体可以在从密码子扫描到下一个密码子时“回收” tRNA,从而提高翻译效率。根据该模型,预期密码子重复率与蛋白质表达水平显示正相关。其次,已知某些氨基酸重复序列(例如富含脯氨酸的片段)会通过诱导核糖体失速而降低翻译效率。 (请参阅最近的评论23)。这表明氨基酸重复率与蛋白质表达水平负相关。最后,最重要的是,密码子重复率和氨基酸重复率不是独立的,因为密码子重复必须翻译成氨基酸重复。因此,这些序列特征的联合效果可能会很复杂。例如,增加的密码子重复率本身暗示更高的蛋白质表达水平,由于氨基酸重复率增加的反作用,可能导致较低的蛋白质表达水平。总而言之,我们推测这些序列特征的物种特异性影响可能反映了它们在红细菌和大肠杆菌中的影响之间的不同平衡,这是由于例如核糖体机械结构和/或tRNA基因拷贝数的差异。尽管无法在本研究中对此类可能原因进行剖析,但我们的结果将作为一个实例,说明序列特征对蛋白质表达水平的物种特异性影响。
在密码子优化方法的发展中,首先设计了仅基于mRNA折叠能的H方法(图2),然后通过结合密码子频率将其改进为C方法(图4)。这是由于我们实验数据的反馈所致,即其蛋白质表达水平不能被H方法提高的基因含有稀有密码子(图3)。这种反馈策略对于开发除红球菌以外的宿主生物(包括细菌,真菌,昆虫和哺乳动物)的密码子优化方法也可能有用。
在C方法的验证实验中(图4),测试的12个基因中有9个(75%)达到了增加的表达水平。特别是对于野生型序列表达水平很小或无法检测到的5个基因,通过密码子优化改善了所有这些基因。另一方面,其余3个基因未观察到改善。我们注意到,即使在密码子优化之前使用野生型序列,这些基因的表达水平也相对较高。他们在我们的数据集(补充数据S1)中的表达得分对于2个基因为3(高),对于一个基因为2(中)。因此,一种可能性是这些基因的表达已经处于接近最佳的水平,并且难以通过密码子优化进一步改善。
我们注意到,我们的方法目前存在以下局限性。首先,由于C方法仅考虑ΔGUH和CAIH,因此其他序列特征的参与可能会阻碍蛋白质表达的改善。例如,C方法中CAIH的调节仅考虑了33个头部核苷酸,这表明下游核苷酸中较差的CAI阻碍了改进的可能性。我们确认,这种可能性不适用于C方法验证实验中使用的基因(补充图S4)。失败基因的总体CAI与继承基因没有显示出实质性差异。然而,除了ΔGUH和CAIH之外,还可以通过加入新的序列特征来提高我们方法的成功率。最近,Cambray等人。已使用244,000个基因在大肠杆菌中进行了表达分析24。即使进行了如此大规模的分析,他们也报告了序列特征(与我们的研究相似)仅解释了蛋白质表达水平大约30%的变化,这表明存在未知的序列特征。为了探索这种新的序列特征,将有必要对红细菌和其他宿主生物中的重组蛋白表达进行大规模分析。其次,我们的方法是基于影响翻译效率的序列特征开发的。因此,当表达受翻译效率以外的因素阻碍时,蛋白质表达的改善将受到限制。这些因素包括膜分选,S-S键形成以及要表达的蛋白质的毒性。我们注意到,本研究中使用的所有蛋白质均为细胞质蛋白质,不包括跨膜蛋白质或具有S-S键的蛋白质(补充数据S1)。尽管蛋白质的选择使我们能够开发和评估侧重于翻译效率的方法,但本研究未解决基于其他因素的改进。
在本研究中,我们解决了密码子优化方法主要用于提高表达水平的问题。另一方面,还需要降低表达水平,其中包括减弱代谢途径中不必要的通量以改善目标代谢物的产生25。在这方面,我们的方法也可能有用,因为通过对mRNA折叠能量进行去优化而设计的L系列序列成功降低了大多数受测基因的表达水平(图2)。这项研究中未解决的另一个问题是表达水平的微调,即不仅要简单地最大化或最小化表达水平,还要将表达水平调节在所需水平26。为此目的,可以通过选择具有中等序列特征值而不是具有最大值或最小值的同义变体来设计编码序列。这些要点应作为将来的方向。
2.4 方法
- CAI()和tAI的计算方法如上所述,是从密码子使用数据库(登录号为234621)中获得的红血球菌的基因组密码子使用。
- 对于tAI,计算了权重矩阵(也称为密码子-tRNA相互作用矩阵),通过先前研究中提出的方法。简而言之,我们考虑了R. erythropolis的遗传基因中的tRNA基因的拷贝数和密码子使用偏倚来调整权重矩阵。所得的权重矩阵可在作者的GitHub网站上获得。
- 密码子重复率是通过[数学运算错误]计算的,其中di是从每个密码子位置到同一类型密码子的下一个出现位置的距离,L是序列长度。
- 氨基酸重复率的计算方法类似,不同之处在于重复是针对编码的氨基酸类型而不是密码子类型进行计数的。
- ΔGUH由EnsembleEnergy程序版本5.8.1在RNAstructure程序包中计算。为了进行统计分析,使用R软件中的polycor软件包版本0.7.9计算了多序列相关系数及其p值。 CAIH的计算方法与CAI类似,只针对33个头部核苷酸(即11个密码子)进行计算。稀有密码子定义为归一化密码子频率小于0.1的密码子。对于每种类型的密码子c,归一化的密码子频率定义为wc = fc / maxs fs,其中f是一个基因组密码子频率,而s是一个与c编码相同氨基酸的同义密码子。
试验略
参考资料
