【2.4】illumina 二代测序原理及过程
一、Library Preparation 文库的构建
文库,就是 DNA 片段的一个集合。将测序片段打断之后就构成了一个 DNA 文库。简单来说就是把 DNA 分子用超声波打断成一定长度范围的小片段。目前除了一些特殊的需求之外,基本都是打断为 300bp-800bp 长的序列片段,并在这些小片段的两端添加上不同的接头,构建出单链 DNA 文库,以备测序之用。
1.1 目的
文库需满足捕获 DNA/RNA、cluster、测序、数据分析的过程。
1.2 文库分类
- DNA 类文库:DNA 小片段文库、DNA 大片段文库、Exon 文库、PCR-Free 文库、简化基因组文库、单细胞样本文库等。
- DNA 小片段文库:片段大小在 1Kb 以下的普通 DNA 文库,可用来进行人重测序,动植物、微生物的 de novo 和重测序,16s rRNA 测序,宏基因组测序等项目类型的文库构建。
- RNA 类文库:转录组文库、表达谱 (RNA-Seq)、Small RNA。
详见:Illumina 平台测序原理及常见测序文库构建详细版。pptx
二、DNA 小片段建库流程
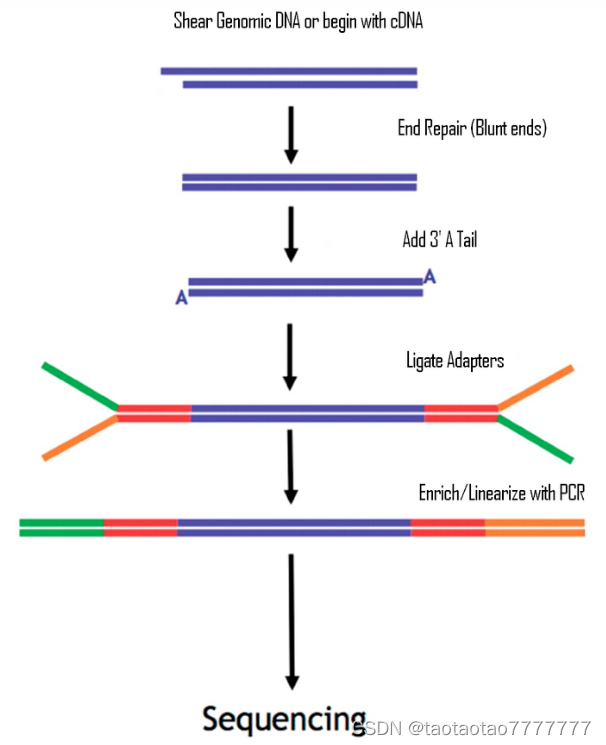
1. 基因组 DNA 片段化:对 DNA 样品按需进行随机打断
- DNA 打断方法:机械打断、超声波打断,酶解法打断等。超声波打断可以设定打断的长度,常见的文库长度有 170bp 文库、350bp 文库、500、800、2k、5k、6k 甚至更长的 10K,20K 等,一般 1000bp 以下,称为小片段文库,否则是大片段文库。
- 注意,我们说 500bp 文库,这个 500 只是一个峰值。也就是里面大部分的片段在 500bp 附近,并不是每条片段都刚好是 500bp,可能有 300, 的,也可能有 800 的。在打断之后会有一个电泳的过程,将在一定范围内的回收。如果是 500bp 文库,可以回收 300-800bp 长度的片段。这个文库大小特别重要,也叫做插入片段长度 insert_size。在后面序列拼接,短序列比对的过程中会大量用到这个值。
2.末端补平
T4 DNA polymerase & DNA polymerase I (Klenow)。促进 DNA 向 5’→3’ 方向聚合;是 3’→5’外切核酸酶,有 3’→5’外切酶活性;无 5’→3’外切核酸酶活性。
3. 片段 3’端加 A 尾
用 Klenow 酶给 3’端加一个 A 碱基,在加了 A 碱基之后,原来的平末端就变成了粘性末端,这样更容易链接后面的引物和接头等。加完 A 碱基之后还需要加测序引物。
4.连接接头 Adapter
经过末端修饰的 PCR 片段的末端具有突出的 A 尾,而接头具有突出的 T 尾,可以使用 T4 DNA 连接酶将接头添加到 DNA 片段的两边,添加接头主要是为了后续 PCR 中作为引物扩增时可以继续添加 index 等修饰。
5.修饰接头
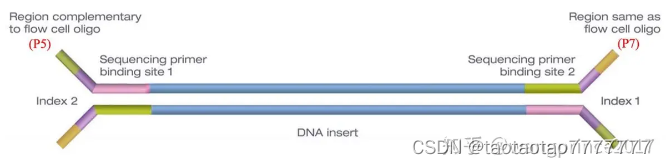
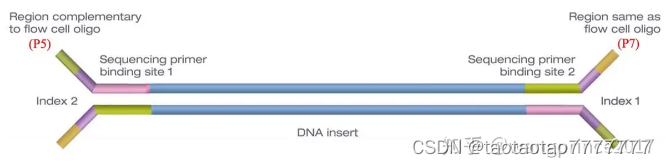
接头连接成功后,利用低循环扩增技术在接头处进行修饰,分别在两端添加 sequencing primer binding site1 / 2(测序引物结合位点)、index1/index2 以及我们称之 P5 和 P7 的寡核苷酸序列。
- index,也叫 Barcodes,是一个 6-8bp 的片段,对文库中的接头进行标记。因为一个 lane 可以同时测多个样品,为了避免混淆样品的 read products,每种样品的 DNA 由一种 index 修饰,这样测序得到的 reads 都是具有 index 标记的,在测序结果中,依据之前标签与样品的对应关系,就可以获得对应样品的数据。而这里的 index1 和 index2 是为了区分 paired-end 测序得到的双端 reads。
- P5 和 P7 是不同的,它们分别和 flowcell 上的接头互补和相同。
- index1 和 index2 也是不同的,与 P5 相连的是 index2,与 P7 相连的是 index1。
6. 对 DNA 进行片段筛选
添加接头后的体系中含有聚合酶、连接酶等各种酶,接头的添加也是过量的,而且也可能会有大片段的存在,所以需要用磁珠进行双筛来去除大片段以及各种杂质,从而获得成功添加接头的文库片段,双筛时要根据不同的文库片段来控制磁珠添加量,若添加了 PEG 等增强剂,则需要先进行纯化,再继续双筛。
7.PCR 扩增
加了接头的 DNA 片段,用与接头互补的引物来进行扩增。PCR 后需要再次进行磁珠纯化,将产物与杂质分离。
8.PCR 产物质检
用 Qubit DNA HS ASSAY KIT 对 PCR 产物进行定量;进行 2100 High SensitivityDNA Chip 电泳,判断片段大小是否符合后续测序要求(片段大小一般为 400bp 左右);通过 Qubit 定量结果和 2100 chip 检测出的片段大小计算摩尔浓度。
General Bar-coding Strategy
barcode/index 的选择有两个原则:碱基平衡和激光平衡。
- 碱基平衡是指的需要兼顾 barcode 序列的平衡度与复杂度,平衡度是指的碱基的比例是均衡的(1:1 是最均衡的。注意,是多个待测样品 barcode 之间的平衡,并非一个 barcode 内部的碱基平衡);而复杂度是指的碱基的种类是多样的(四种碱基同时存在是最多样的)。最好的 barcode 序列应该是同时有 A、T、G、C 四种碱基,且各碱基所占比例近似均为 25% 。
- 激光平衡就是尽量在使用的一组 barcode 中满足每个碱基位都是 A+C=G+T。
- 既不满足碱基平衡,又不满足激光平衡的 barcode 将会有很大的数据分离隐患,或者无法分离开样品,或者无法识别某些测序片段。
三、lllumina 桥式 PCR 扩增 —— Cluster generation 簇生成
- Flowcell(流动池)是有 2 个或 8 个 lane(泳道)的玻璃板,每个 lane 可以测一个样本或者多样本的混合物,且随机布满了能够与文库两端接头分别互补配对或一致的寡核苷酸(oligos,P7 和 P5 接头)。一个 lane 包含两列,每一列有 60 个 tile,每个 tile 会种下不同的 cluster,每个 tile 在一次循环中会拍照 4 次(每个碱基一次)。

-
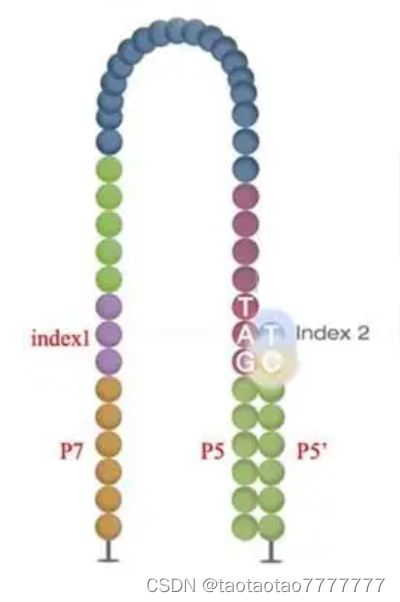
P5 和 flowcell 上的接头互补;P7 和 flowcell 上的接头相同。为了方便阐述,与 P5 互补的接头称为 P5’,与 P7 互补的接头称为 P7’。
-
与 P5 相连的是 index2,与 P7 相连的是 index1。
过程:
- Flowcell 上随机分布了两种不同的寡核苷酸接头,分别与 P5 互补(即 P5') , 与 P7 相同(即 P7)。待测 DNA 文库加入后,接头上的 P5 与 flowcell 上的 P5’接头杂交互补,以待测序列为模板进行互补链(即 reverse strand)的延伸,互补链的两端为 P5’和 P7’;
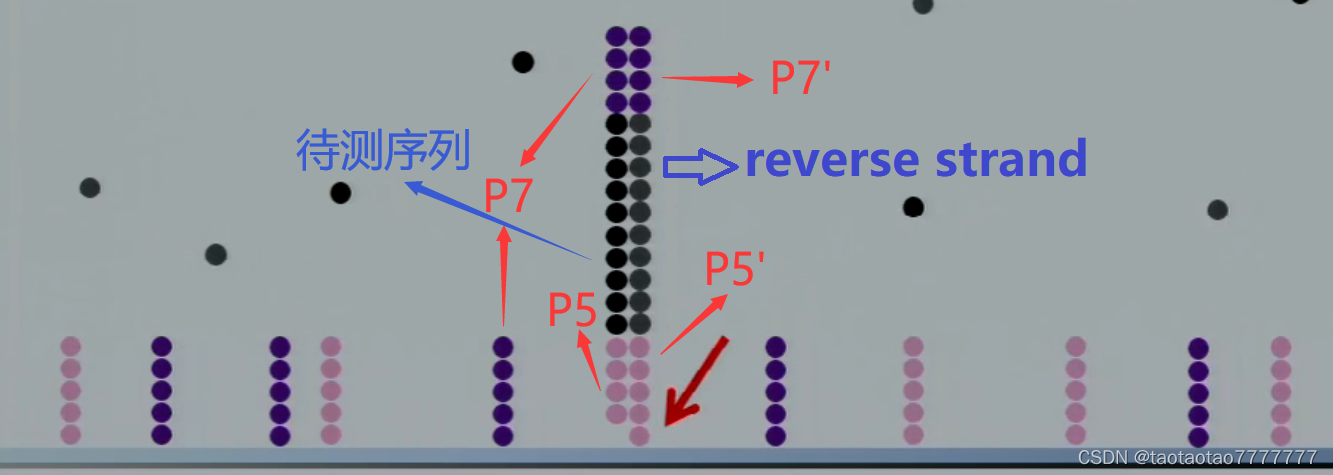
- 加入的模板链没有固定在板子上,被切断并洗下,留下新延伸出的 reverse strand,reverse strand 的 P7’与 Flowcell 上的 P7 杂交互补,退火后会与附近的 p7 接头配对进行链的合成,即 桥式 PCR。合成的双链被解链,再分别与 Flowcell 上邻近的接头杂交互补,延伸,解链,杂交,延伸,解链。… 如此重复 35 个循环。此时扩增出的链都是固定在板子上的,呈指数扩增。最终形成以 reverse strand 为模板,在周围复制形成簇 cluster。

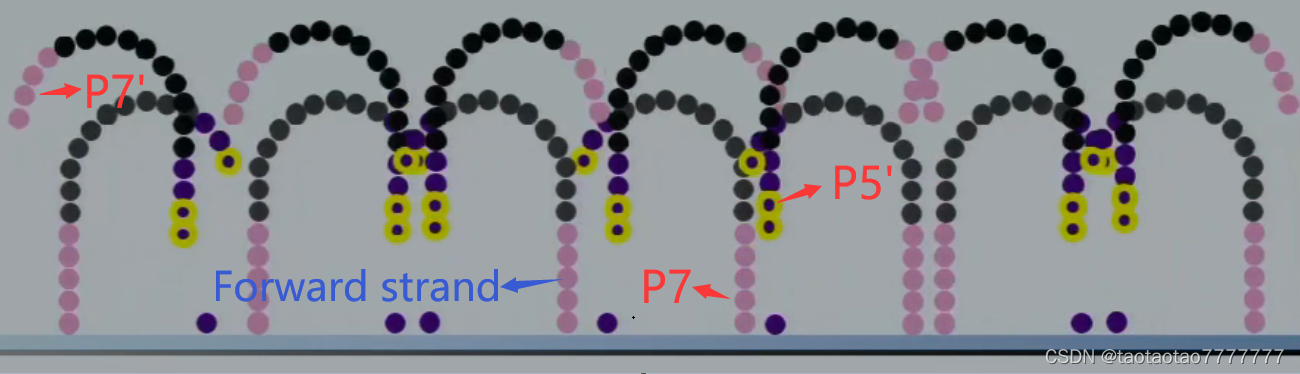
- 桥式 PCR 完成后,使用 NaOH 将双链解链,并利用甲酰胺基嘧啶糖苷酶(Fpg)对 8-氧鸟嘌呤糖苷(8-oxo-G)的选择性切断作用,选择性地将 P5’与 reverse strand 的连接切断,只留下与 Flowcell 上 P7 连接的链,即 Forward strand,保证后续合成读取时的方向一致。同时游离的 3’端被阻断,防止不必要的 DNA 延伸。
四、lllumina 测序
1. 加入测序引物(sequencing primer)、四种 dNTP、DNA 聚合酶。
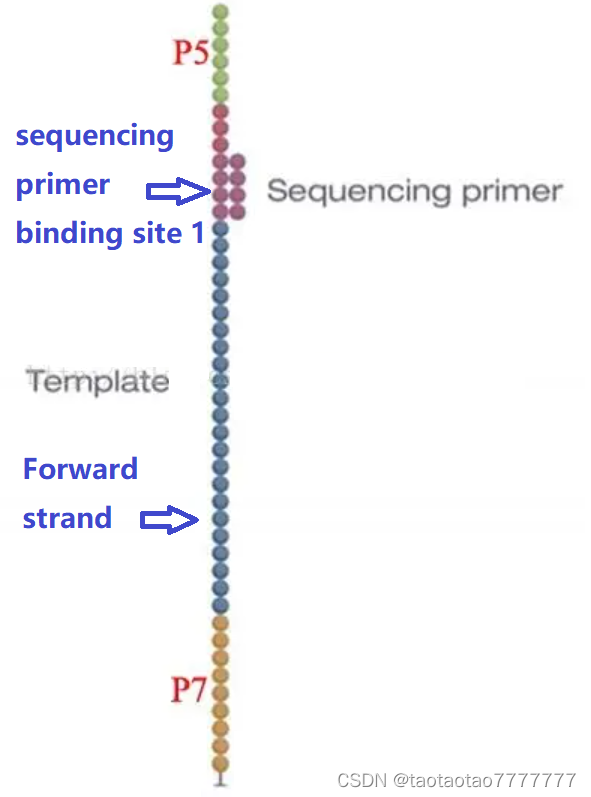
测序引物结合到靠近 P5 的测序引物结合位点 1(sequencing primer binding site 1)上。在聚合酶的作用下,与 Forward strand 相应位置碱基配对的 dNTP 就会结合到新合成的链上,而由于叠氮基的存在,后面的 dNTP 无法继续连接。这时用水将剩余的 dNTP 和酶给冲掉,将 Flowcell 进行扫描,扫描出来的荧光对应的碱基的配对碱基即是该链该位置的碱基。同时在这个 Flowcell 上有成千上万个 cluster 也在进行同样的反应,因此一个循环就能同时检测多个样本(这也是高通量的核心所在)。这个循环完成后,加入化学试剂把叠氮基和标记的荧光基团切掉,进行下一个循环(碱基的连接、检测与切除)。如此重复直至所有链的碱基序列被检测出,也就是 Forward read 序列(Read1)。
dNTP 有两个特点:
- 有荧光基团标记,每种碱基标记的荧光基团不一样;
- 3’末端连了一个叠氮基,这个叠氮基能够阻断后面的碱基与它相连。
2. Index1 测序
如上图中,测序方向是从上往下读取的,那意味着一次只能读取一个方向。所有循环结束后,一个方向读完,用 Buffer 洗掉 read products。加入 index1 primer,与链上 index primer1 结合位点杂交配对,进行 index1 的合成及检测。Index1 测序完成后,洗脱测序产物,此时机器已通过荧光得到了 index1 的序列。

3. Index2 测序
Forward strand 顶端的 P5 序列与 Flowcell 上的 P5’杂交配对,进行 index2 测序。测序完成后洗脱产物。
4. Paired-end sequencing (即对 Reverse strand 测序)
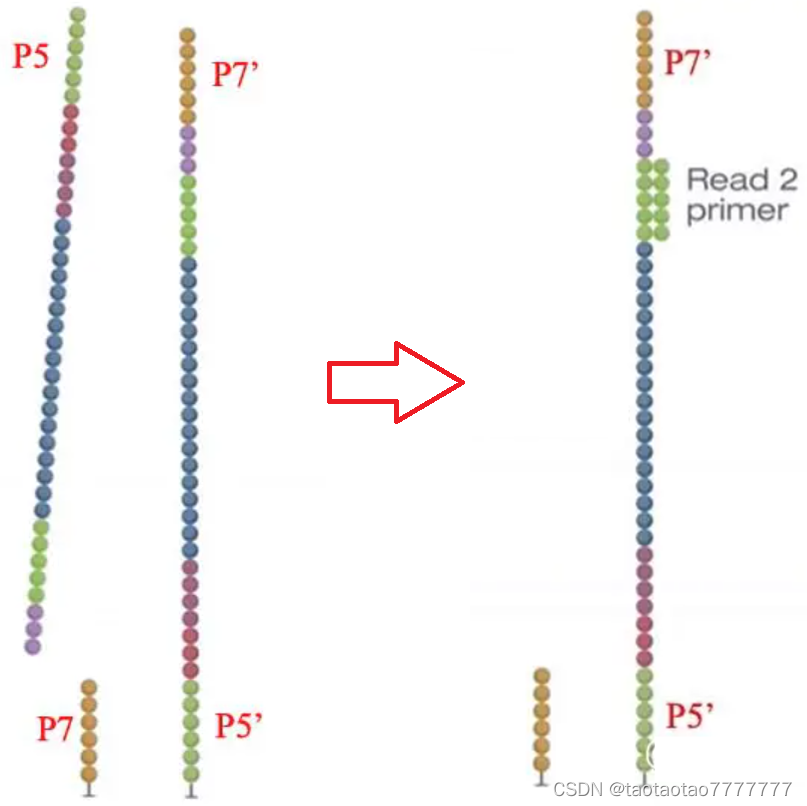
洗脱 index2 测序产物后,以 Flowcell 上的 P5’ 为引物,Forward strand 为模板进行桥式 PCR 扩增,得到双链。扩增后,NaOH 使双链变性为单链,并洗去已经测序完成的 Forward strand。然后,与前面类似,read primer2 结合到靠近 P7’的 read primer binding site 2 开始对 Reverse strand 的测序。测序完成后即可得到 Reverse read 序列(Read2)。
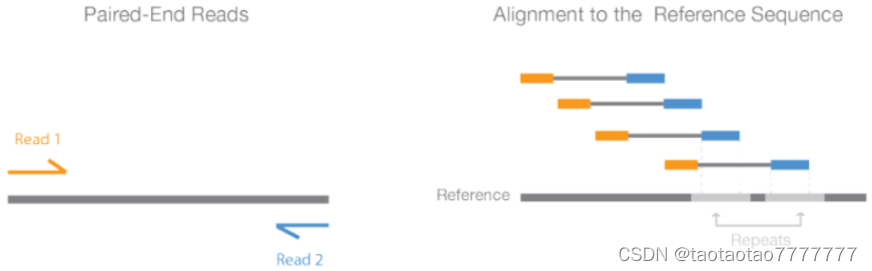
- illumina 的双末端测序:在打断的 DNA 片段两头正反方向各测两个片段,可以通过一定算法来进行序列组装,比对等一系列操作, 对于基因片段的重复、缺失和插入来讲,这种方法更加精确(具体算法参考相关文献),而且读长也更长,在基因组上的覆盖面更广。
- 在双链测序的过程中,如果正负链完全测通(例如测序仪读长为 150bp,待测的序列长度<= 150bp) 测序的末端可能包含 adapter 序列,需要利用软件将 adapter 去除。
- illumina 的这种每次只添加一个 dNTP 的技术特点能够很好的地解决同聚物长度的准确测量问题,它的主要测序错误来源是碱基替换,目前它的测序错误率 1%-1.5% 左右。
参考资料
